Contents
| 2021-12-03 | 21-12-03 | | | Reproducible scientific articles | Reproducible science |
| 2021-01-04 | 21-01-04 | | | Normalized GPs | Normalized GPs |
| 2021-01-03 | 21-01-03 | | | Interpretable GPs for stellar rotation (Part 3) | Interpretable GPs III |
| 2020-10-27 | 20-10-27 | | | Synthetic Likelihoods | Synthetic Likelihoods |
| 2020-10-01 | 20-10-01 | | | Interpretable GPs for stellar rotation (Part 2) | Interpretable GPs II |
| 2020-09-24 | 20-09-24 | | | Interpretable GPs for stellar rotation (Part 1) | Interpretable GPs I |
| 2020-09-17 | 20-09-17 | | | So I started a blog... | So I started a blog... |

In this post I'll talk a bit about showyourwork!, the open source scientific article workflow I've been working on for the past few months. It's still very much a work in progress, but you can already use it in your own research to ensure the reproducibility of your results! If you're interested, please check out the GitHub repository and the documentation.
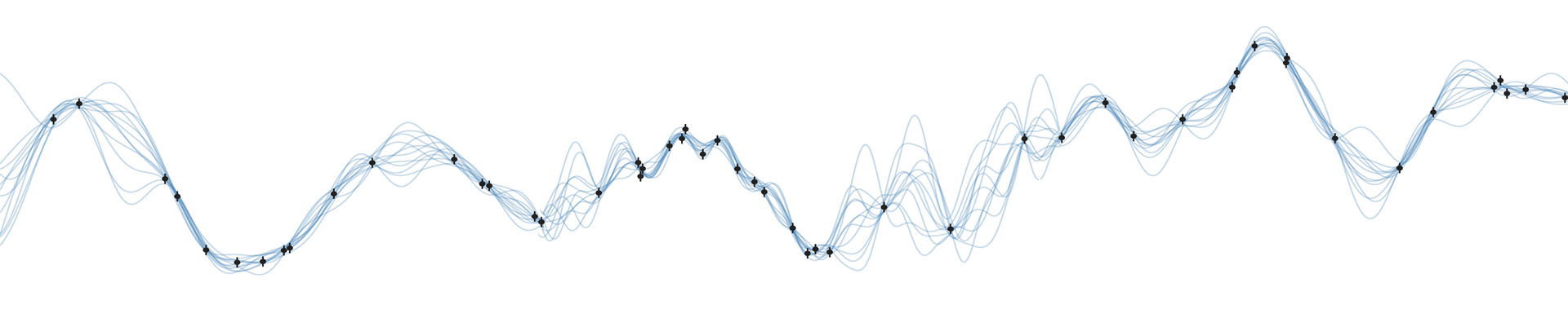
I ran into an interesting statistics problem while working on my interpretable Gaussian process for stellar light curves (see this post). What happens to the covariance structure of a dataset when we normalize it to its own mean (or median)? This is something that happens a lot in the literature: astronomers love normalizing light curves to sweep the unknown baseline under the rug and convert their data in relative units. But it turns out that this is sometimes a dangerous thing to do, since it can significantly change the covariance structure of the data. In this post I'll show an example of this, how it can bias GP inference, and how to fix it.
Continue Reading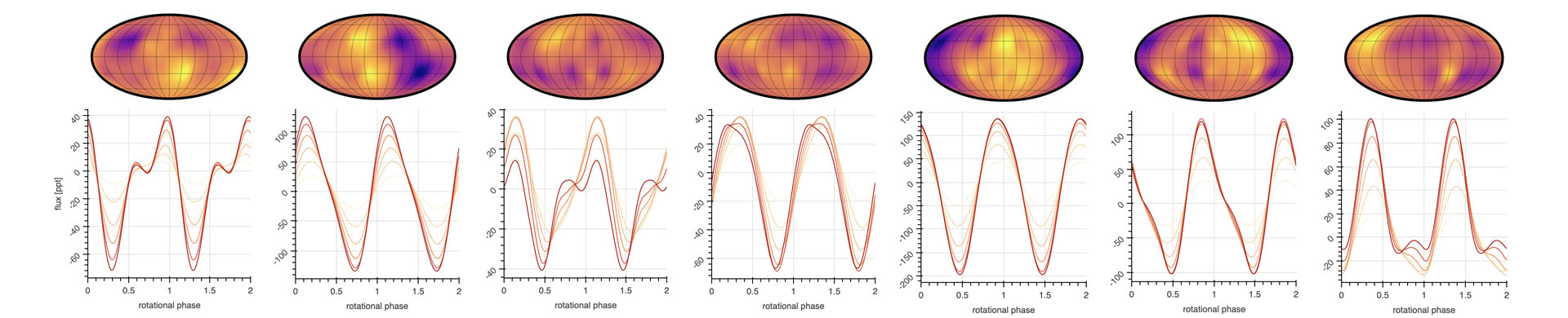
This is a (long overdue) continuation of a previous post, in which I discussed the development of an interpretable Gaussian process for stellar light curves. This post is mainly a wrapper for a talk I gave a couple months ago on the topic, so if you have 20 minutes (and an interest in stellar light curve modeling), please check it out!
Continue Reading
In this post I dig a little deeper into the assumptions I'm making when I try to model stellar surfaces (and, equivalently, stellar light curves) using a Gaussian Process. The true likelihood function for the data is certainly not a gaussian, but it turns out that approximating it as such is not a terrible idea. Here I'll discuss the concept of a synthetic likelihood, which is a term from the ecology literature (and is probably called different things in different fields), and explore its behavior with a very simple toy model. I'll warn you right now that I'm in a bit over my head with this, so comments / thoughts from proper statisticians are most welcome!
Continue Reading
This is a continuation of the previous post, in which we implemented a very slow, inefficient, and numerically unstable Gaussian process for stellar light curves. In this post I'll discuss how to compute the GP kernel analytically and show how to use this GP to learn about star spot properties from stellar light curves.
Continue Reading
As I discussed in my previous post, the information content of stellar light curves can be exceptionally tiny, owing to the large number of degeneracies when projecting from a two-dimensional space (the stellar surface) to a one-dimensional curve (the flux timeseries). Instead of trying to produce a definitive map of a stellar surface from a light curve, we can instead model the surface as a statistical process. In this post, I discuss ongoing work to develop a Gaussian process for stellar light curves whose hyperparameters are rooted in statistical properties of the stellar surface.
Continue Reading
Ever since I started my postdoc at the CCA, it feels like I've started a million different projects (and finished none). I have a lot of half-finished (or more like half-baked) ideas that I felt I had to write down somewhere, so I decided to start a blog! This blog will be a mishmash of posts on astronomy, data science, math, and any other random thoughts that pop into my head.
Continue Reading